
반응형
ChatGPT로 Python pandas 알아보기 (9) : 기초통계량

'기초통계량'이란?
기초 통계량은 데이터의 기본적인 특성을 요약하여 표현하는 수치들을 말한다.
이러한 기초 통계량은 데이터를 분석하고 이해하는 데 있어 중요한 역할을 하며, 통계적 추론의 기초가 된다.
기초 통계량에는 여러 종류가 있는데, 대표적으로 다음과 같은 것들이 있다.
이를 통해 데이터의 중심, 퍼짐, 비대칭성 등을 쉽게 이해하고 분석할 수 있다.
이러한 기초 통계량은 데이터를 분석하고 이해하는 데 있어 중요한 역할을 하며, 통계적 추론의 기초가 된다.
기초 통계량에는 여러 종류가 있는데, 대표적으로 다음과 같은 것들이 있다.
- 평균 (Mean): 모든 데이터 값을 합한 후, 데이터의 개수로 나눈 값으로, 데이터의 중심 경향을 나타낸다.
- 중앙값 (Median): 데이터를 크기 순으로 나열했을 때, 가장 가운데에 위치하는 값이다.
데이터의 분포가 치우친 경우, 평균보다는 중앙값이 더 대표적인 값을 나타낼 수 있다. - 최빈값 (Mode): 데이터셋에서 가장 자주 등장하는 값으로, 어떤 값이 데이터 내에서 가장 흔한지를 나타낸다.
- 표준편차 (Standard Deviation)와 분산 (Variance): 데이터 값들이 평균으로부터 얼마나 퍼져있는지를 나타내는 척도이다.
표준편차는 분산의 제곱근으로, 분산보다 더 직관적으로 데이터의 퍼짐 정도를 이해할 수 있다. - 사분위수 (Quartiles): 데이터를 4등분하는 값들로, 제1사분위수(Q1)는 하위 25%, 제2사분위수(Q2)는 하위 50%(=중앙값), 제3사분위수(Q3)는 하위 75%에 해당하는 값이다.
사분위수를 이용하면 데이터의 분포를 더 상세히 이해할 수 있다.
이를 통해 데이터의 중심, 퍼짐, 비대칭성 등을 쉽게 이해하고 분석할 수 있다.
pandas 기초통계량 Method
우선 pandas에는 다음과 같은 기초통계량 메서드를 제공한다.
우선 아래와 같은 샘플 데이터를 사용하겠다.
우선 아래와 같은 샘플 데이터를 사용하겠다.
import pandas as pd
import numpy as np
# A와 B는 모두 0~100 중에 무작위로 20개를 생성한다.
df = pd.DataFrame({
'A': np.random.randint(0, 101, size=20),
'B': np.random.randint(0, 101, size=20)
})

✔ count()
NA 값을 제외한 수를 반환하는 메서드이다.
NA 값을 제외한 수를 반환하는 메서드이다.
df.count()
✔ describe()
각 열에 대한 요약 통계를 계산하는 메서드이다.
각 열에 대한 요약 통계를 계산하는 메서드이다.
df.describe()
✔ min()
최솟값을 계산하는 메서드이다.
최솟값을 계산하는 메서드이다.
df.min()
✔ max()
최댓값을 계산하는 메서드이다.
최댓값을 계산하는 메서드이다.
df.max()
✔ sum()
데이터의 합을 계산하는 메서드이다.
데이터의 합을 계산하는 메서드이다.
df.sum()
✔ mean()
데이터의 평균을 계산하는 메서드이다.
데이터의 평균을 계산하는 메서드이다.
df.mean()
✔ median()
데이터의 중위수(중앙값)을 출력하는 메서드이다.
데이터의 중위수(중앙값)을 출력하는 메서드이다.
df.median()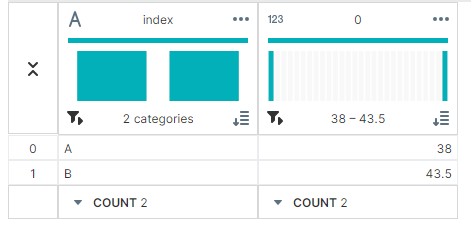
✔ var()
데이터의 분산을 계산하는 메서드이다.
데이터의 분산을 계산하는 메서드이다.
df.var()
✔ std()
데이터의 표준편차를 계산하는 메서드이다.
데이터의 표준편차를 계산하는 메서드이다.
df.std()
✔ argmin()
데이터 중 최솟값을 가진 index를 출력한다.
argmin()은 Series에서 사용한다.
데이터 중 최솟값을 가진 index를 출력한다.
argmin()은 Series에서 사용한다.
df['A'].argmin()
df['B'].argmin()
✔ argmax()
데이터 중 최댓값을 가진 index를 출력한다.
argmax()은 Series에서 사용한다.
데이터 중 최댓값을 가진 index를 출력한다.
argmax()은 Series에서 사용한다.
df['A'].argmax()
df['B'].argmax()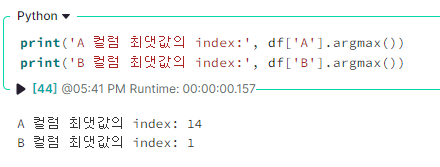
✔ idxmin()
데이터에서 최솟값의 index를 출력한다.
각 컬럼별의 argmin() 결과를 출력해준다.
데이터에서 최솟값의 index를 출력한다.
각 컬럼별의 argmin() 결과를 출력해준다.
df.idxmin()
✔ idxmax()
데이터에서 최댓값의 index를 출력한다.
각 컬럼별의 argmax() 결과를 출력해준다.
데이터에서 최댓값의 index를 출력한다.
각 컬럼별의 argmax() 결과를 출력해준다.
df.idxmax()
argmin(), argmax(), idxmin(), idxmax()는 중복된 최솟값 또는 최댓값이 있을 경우, 기본적으로 가장 첫번째 index를 반환한다.
✔ quantile()
데이터의 특정 사분위수에 해당하는 값을 반환한다.
데이터의 특정 사분위수에 해당하는 값을 반환한다.
df.quantile(q)
# q는 0과 1사이의 값으로 입력한다. / list로도 입력 가능하다.
df.quantile([0.25, 0.5, 0.75])
위 코드에서 0.25는 25%로 제1사분위수를, 0.5는 50%로 중앙값을, 0.75는 75%로 제3사분위수를 출력한다.

✔ cumsum()
데이터의 누적합을 계산한다.
데이터의 누적합을 계산한다.
df.cumsum()
✔ cumprod()
데이터의 누적곱을 계산한다.
데이터의 누적곱을 계산한다.
df.cumprod()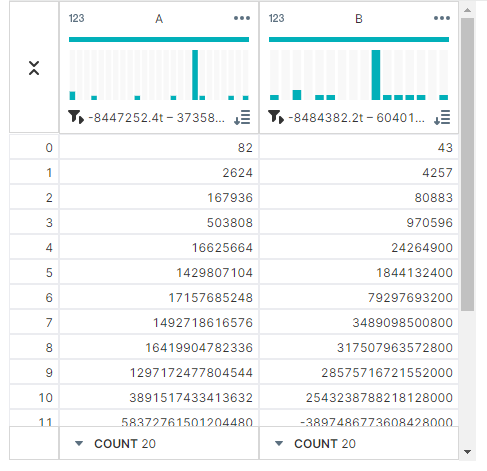
Summary
위 내용들을 요약하자면 아래와 같다.
- count(): NA 값을 제외한 수를 반환.
- describe(): Series나 DataFrame의 각 열에 대한 요약 통계를 계산.
- min(), max(): 최솟값, 최댓값을 계산.
- sum(): 합을 계산.
- mean(): 평균을 계산.
- median(): 중위수를 출력.
- var(): 분산을 계산
- std(): 표준편차를 계산.
- argmin(), argmax(): Series에서 최솟값, 최댓값을 가진 index를 출력.
- idxmin(), idxmax(): 최솟값, 최댓값을 가진 index를 출력.
- quantile(): 특정 사분위수에 해당하는 값을 반환.
- cumsum(): 누적합을 계산.
- cumprod(): 누적곱을 계산.
ChatGPT로 pandas 라이브러리에서 사용하는 기초통계량 관련 메서드에 대해서 알아보았다.
오랜만에 전공 공부하는 느낌 같아서 뭔가 재미있었고, 처음보는 메서드도 몇개 있어서 재미있는 시간이었던 것 같다.
오랜만에 전공 공부하는 느낌 같아서 뭔가 재미있었고, 처음보는 메서드도 몇개 있어서 재미있는 시간이었던 것 같다.
반응형
'Python > Pandas' 카테고리의 다른 글
| ChatGPT로 Python pandas 알아보기 (8):데이터 병합 (6) | 2023.06.14 |
|---|---|
| ChatGPT로 Python pandas 알아보기 (7):결측치 처리 (6) | 2023.06.13 |
| ChatGPT로 Python pandas 알아보기 (6):데이터 그룹화 및 집계 (0) | 2023.06.12 |
| ChatGPT로 Python pandas 알아보기 (5):데이터 정렬 (5) | 2023.06.11 |
| ChatGPT로 Python pandas 알아보기 (4):DataFrame method (3) | 2023.06.10 |





ChatGPT에서 플러그인인 Noteable을 사용해서 기초통계량 관련 내용과 메서드들을 정리 및 설명을 요청해보았다.
작성해준 내용을 바탕으로 내용을 정리해보았다.