
반응형
ChatGPT로 Python pandas 알아보기 (8):데이터 병합

merge() 메서드
pandas의 merge 메서드는 두 데이터프레임을 특정 열(들)을 기준으로 병합하는데 사용된다.
이 메서드의 기본 문법은 다음과 같다.
이 메서드의 기본 문법은 다음과 같다.
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, suffixes=('_x', '_y'))| left | 첫 번째 데이터프레임 |
|---|---|
| right | 두 번째 데이터프레임 |
| how | 조인 방식을 결정 ('inner', 'outer', 'left', 'right' 중 선택) |
| on | 조인할 기준 열의 이름. 두 데이터프레임에서 이름이 같아야 한다. |
| left_on | left 데이터프레임의 열 이름으로, 조인할 기준 열로 사용된다. |
| right_on | right 데이터프레임의 열 이름으로, 조인할 기준 열로 사용된다. |
| suffixes | 중복되는 열 이름에 대해 접미사를 지정할 수 있다. 기본값은 ('_x', '_y')이다. |
✔ Inner Join
'학번'을 기준으로 df1과 df2를 Inner join을 한다면 아래처럼 쓸 수 있다.
Inner Join이란 두 개 이상의 테이블에서 조인할 때, 특정 기준 열(column)에 공통으로 존재하는 값들을 기준으로 데이터를 결합하는 방법이다.
'학번'을 기준으로 df1과 df2를 Inner join을 한다면 아래처럼 쓸 수 있다.
Inner Join이란 두 개 이상의 테이블에서 조인할 때, 특정 기준 열(column)에 공통으로 존재하는 값들을 기준으로 데이터를 결합하는 방법이다.
merged_inner = pd.merge(df1, df2, on='학번', how='inner')
▶ 출력 결과

Inner Join
✔ Outer Join
'학번'을 기준으로 df1과 df2를 Outer join을 한다면 아래처럼 쓸 수 있다.
Outer Join이란 두 개 이상의 테이블에서 조인할 때, 한 테이블에만 존재하는 값들도 포함하여 데이터를 결합하는 방법이다.
'학번'을 기준으로 df1과 df2를 Outer join을 한다면 아래처럼 쓸 수 있다.
Outer Join이란 두 개 이상의 테이블에서 조인할 때, 한 테이블에만 존재하는 값들도 포함하여 데이터를 결합하는 방법이다.
merged_outer = pd.merge(df1, df2, on='학번', how='outer')
▶ 출력 결과
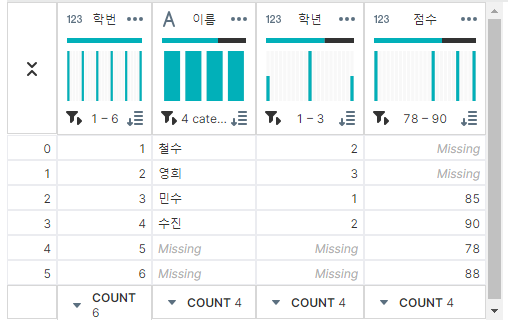
Outer Join
✔ Left Join
Left Join은 Outer Join의 유형으로, 두 개의 테이블에서 첫 번째(왼쪽) 테이블을 기준으로 데이터를 결합하는 방법이다.
Left Join은 Outer Join의 유형으로, 두 개의 테이블에서 첫 번째(왼쪽) 테이블을 기준으로 데이터를 결합하는 방법이다.
merged_left = pd.merge(df1, df2, on='학번', how='left')
▶ 출력 결과

Left Join
✔ Right Join
Right Join도 Outer Join의 유형으로, Left Join과 반대로 작동하며, 두 개의 테이블에서 두 번째(오른쪽) 테이블을 기준으로 데이터를 결합한다.
Right Join도 Outer Join의 유형으로, Left Join과 반대로 작동하며, 두 개의 테이블에서 두 번째(오른쪽) 테이블을 기준으로 데이터를 결합한다.
merged_right = pd.merge(df1, df2, on='학번', how='right')
▶ 출력 결과

Right Join
✔ 데이터프레임의 키(Key)가 다를 때
left_on과 right_on을 사용하여 서로 다른 이름을 가진 열을 조인 키로 사용할 수도 있다.
샘플 데이터프레임인 df1, df2와 키로 사용될 열의 이름이 다른 데이터프레임을 새로 생성해서 진행해보겠다.
left_on과 right_on을 사용하여 서로 다른 이름을 가진 열을 조인 키로 사용할 수도 있다.
샘플 데이터프레임인 df1, df2와 키로 사용될 열의 이름이 다른 데이터프레임을 새로 생성해서 진행해보겠다.
# 새로운 데이터프레임 생성
data3 = {
'student_id': [3, 4, 5, 6],
'성적': [85, 90, 78, 88]
}
df3 = pd.DataFrame(data3)
'학번'과 'student_id'를 기준으로 병합한다면 아래처럼 사용하면 된다.
merged_diff_key = pd.merge(df1, df3, left_on='학번', right_on='student_id', how='inner')
▶ 출력 결과
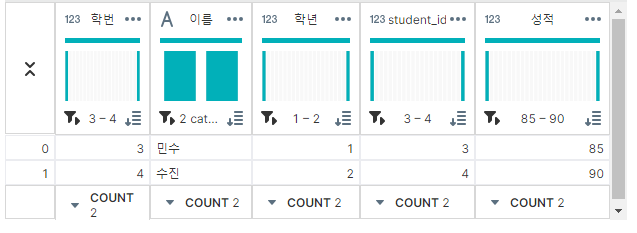
left_on/right_on
✔ suffixes 매개변수
suffixes 매개변수는 merge 메서드를 사용할 때 두 데이터프레임에 같은 이름의 열이 있을 경우, 이를 구별하기 위해 열 이름에 추가되는 접미사를 설정하는 데 사용된다.
이 매개변수는 접미사로 사용될 문자열의 쌍을 받는다. 기본값은 ('_x', '_y') 이다.
새로운 데이터프레임으로 사용 예시를 봐보겠다.
suffixes 매개변수는 merge 메서드를 사용할 때 두 데이터프레임에 같은 이름의 열이 있을 경우, 이를 구별하기 위해 열 이름에 추가되는 접미사를 설정하는 데 사용된다.
이 매개변수는 접미사로 사용될 문자열의 쌍을 받는다. 기본값은 ('_x', '_y') 이다.
새로운 데이터프레임으로 사용 예시를 봐보겠다.
# 첫 번째 데이터프레임
data1 = {
'학번': [1, 2, 3, 4],
'이름': ['홍길동', '이순신', '김유신', '강감찬'],
'성적': [85, 90, 88, 95]
}
df1 = pd.DataFrame(data1)
# 두 번째 데이터프레임
data2 = {
'학번': [3, 4, 5, 6],
'이름': ['장보고', '유관순', '신사임당', '세종대왕'],
'성적': [92, 89, 87, 96]
}
df2 = pd.DataFrame(data2)
위 샘플 데이터프레임에선 모든 컬럼의 이름이 중복된다.
저 상태 그대로 병합을 하게 되면 구분이 어려우니 suffixes 매개변수를 사용해서 접미사를 설정해보겠다.
'학번'을 기준으로 df1과 df2를 병합하고, suffixes 매개변수를 사용하여 접미사 설정하려면 아래처럼 사용하면 된다.
저 상태 그대로 병합을 하게 되면 구분이 어려우니 suffixes 매개변수를 사용해서 접미사를 설정해보겠다.
'학번'을 기준으로 df1과 df2를 병합하고, suffixes 매개변수를 사용하여 접미사 설정하려면 아래처럼 사용하면 된다.
merged_df = pd.merge(df1, df2, on='학번', suffixes=('_첫번째', '_두번째'))
▶ 출력 결과

suffixes
위의 코드에서 suffixes 매개변수는 ('_첫번째', '_두번째')로 설정되어 있다.
따라서, 두 데이터프레임 df1과 df2에 공통으로 존재하는 열 '이름'과 '성적'은 병합된 데이터프레임에서 '이름_첫번째', '성적_첫번째', '이름_두번째', '성적_두번째'로 구별된다.
따라서, 두 데이터프레임 df1과 df2에 공통으로 존재하는 열 '이름'과 '성적'은 병합된 데이터프레임에서 '이름_첫번째', '성적_첫번째', '이름_두번째', '성적_두번째'로 구별된다.
concat() 메서드
concat 메서드는 주로 여러 데이터프레임을 수직으로 연결(위아래로 합치기)하는 데 사용된다.
하지만 keys와 axis 매개변수를 조정하여 좀 더 복잡한 연산도 수행할 수 있다.
concat의 기본 문법은 아래와 같다.
하지만 keys와 axis 매개변수를 조정하여 좀 더 복잡한 연산도 수행할 수 있다.
concat의 기본 문법은 아래와 같다.
pandas.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, sort=False)| objs | 연결할 데이터프레임들을 리스트로 전달한다. |
|---|---|
| axis | 연결 방향을 결정. 0이면 수직으로(위/아래), 1이면 수평으로(좌/우) 연결한다. |
| join | 연결할 때 인덱스를 기준으로 어떻게 조인할지 결정한다. 'outer'면 두 데이터프레임의 모든 행을 포함하고, 'inner'면 공통 행만 포함한다. |
| ignore_index | True로 설정하면, 연결 후 인덱스를 0부터 다시 부여한다. |
| keys | 여러 데이터프레임을 연결할 때 각각의 데이터프레임에 대한 계층적 인덱스를 생성하는 데 사용된다. |
| sort | 열을 사전 순서로 정렬할지 여부를 결정한다. |
✔ 수직으로 연결
두 데이터프레임을 수직 연결한다면 아래처럼 사용하면 된다.
두 데이터프레임을 수직 연결한다면 아래처럼 사용하면 된다.
# 데이터프레임 생성
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
# 데이터프레임 수직으로 연결
result = pd.concat([df1, df2])
▶ 출력 결과
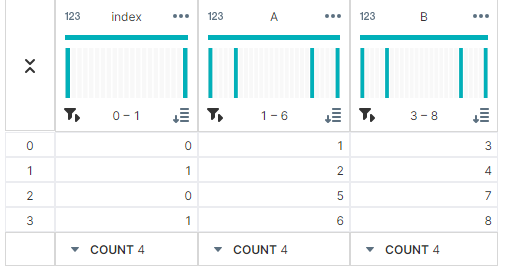
수직 연결
✔ 수평으로 연결
두 데이터프레임을 수평 연결한다면 axis를 1로 설정한다.
두 데이터프레임을 수평 연결한다면 axis를 1로 설정한다.
# 데이터프레임 생성
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'C': [5, 6], 'D': [7, 8]})
# 데이터프레임 수평으로 연결
result = pd.concat([df1, df2], axis=1)
▶ 출력 결과

수평 연결
✔ 계층적 인덱스 사용
데이터프레임 수직으로 연결하면서 계층적 인덱스 사용한다면 아래처럼 사용하면 된다.
Noteable에서는 keys를 사용하면 에러가 발생해서, VS Code의 노트북에서 진행했다.
데이터프레임 수직으로 연결하면서 계층적 인덱스 사용한다면 아래처럼 사용하면 된다.
Noteable에서는 keys를 사용하면 에러가 발생해서, VS Code의 노트북에서 진행했다.
# 데이터프레임 생성
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
# 데이터프레임 수직으로 연결하면서 계층적 인덱스 사용
result = pd.concat([df1, df2], keys=['first', 'second'])
▶ 출력 결과

계층적 인덱스
join() 메서드
join 메서드는 인덱스를 기준으로 데이터프레임을 결합한다.
merge 메서드와 비슷하지만, join은 기본적으로 인덱스를 사용하여 결합하는 반면, merge는 열을 사용한다.
join의 기본 문법은 아래와 같다.
merge 메서드와 비슷하지만, join은 기본적으로 인덱스를 사용하여 결합하는 반면, merge는 열을 사용한다.
join의 기본 문법은 아래와 같다.
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)| other | 결합할 다른 데이터프레임 |
|---|---|
| on | 결합할 기준 열의 이름. 기본적으로 인덱스를 사용하지만, 이 매개변수를 설정하여 특정 열을 기준으로 할 수 있다. |
| how | 결합 방법으로, 'left', 'right', 'outer', 'inner' 중 하나를 선택할 수 있다. (기본값은 'left') |
| lsuffix, rsuffix | 두 데이터프레임에 동일한 열 이름이 있을 경우, 구분을 위해 왼쪽과 오른쪽 데이터프레임의 열 이름에 추가될 접미사이다. |
| sort | 결합된 데이터프레임을 join 키를 기준으로 정렬할지 여부를 결정한다. (기본값은 False) |
✔ join으로 결합
join으로 두 데이터프레임을 결합할 때는 아래처럼 사용하면 된다.
join으로 두 데이터프레임을 결합할 때는 아래처럼 사용하면 된다.
# 데이터프레임 생성
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}, index=['a', 'b', 'c'])
df2 = pd.DataFrame({'C': [7, 8, 9], 'D': [10, 11, 12]}, index=['a', 'b', 'c'])
# 데이터프레임 결합
result = df1.join(df2)
▶ 출력 결과

join
✔ on 매개변수
아래 코드처럼 df1에 index가 'key'라는 열로 지정되어 있는 경우 아래처럼 on에 index가 되는 열의 이름을 작성해준다.
아래 코드처럼 df1에 index가 'key'라는 열로 지정되어 있는 경우 아래처럼 on에 index가 되는 열의 이름을 작성해준다.
# 데이터프레임 생성
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'key': ['a', 'b', 'c']})
df2 = pd.DataFrame({'C': [7, 8, 9], 'D': [10, 11, 12]}, index=['a', 'b', 'd'])
result = df1.join(df2, on='key')
▶ 출력 결과

join other
✔ how 매개변수
outer join을 사용하여 두 데이터프레임의 모든 키를 기준으로 결합하려면 how 매개변수에 outer를 넣어주면 된다.
how는 merge와 동일하게 사용하면 된다.
outer join을 사용하여 두 데이터프레임의 모든 키를 기준으로 결합하려면 how 매개변수에 outer를 넣어주면 된다.
how는 merge와 동일하게 사용하면 된다.
result = df1.join(df2, on='key', how='outer')
▶ 출력 결과
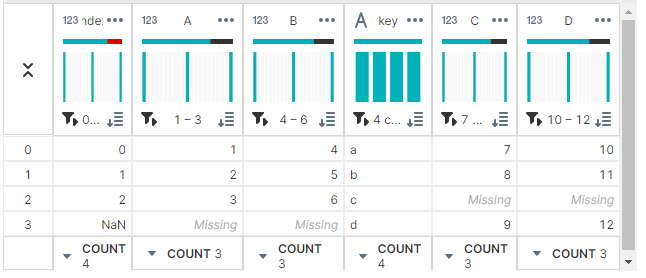
join how
✔ lsuffix와 rsuffix 매개변수
동일한 열 이름이 있을 경우 구분을 위해 접미사를 추가할 때 사용한다.
동일한 열 이름이 있을 경우 구분을 위해 접미사를 추가할 때 사용한다.
df3 = pd.DataFrame({'A': [7, 8, 9], 'B': [10, 11, 12]}, index=['a', 'b', 'c'])
result = df1.join(df3, lsuffix='_left', rsuffix='_right')
▶ 출력 결과

lsuffix / rsuffix
✔ sort 매개변수
join 키에 따라 결과 데이터프레임을 정렬할 때는 sort 매개변수를 사용한다.
join 키에 따라 결과 데이터프레임을 정렬할 때는 sort 매개변수를 사용한다.
result = df1.join(df2, on='key', sort=True)
▶ 출력 결과

join sort
이번 포스트에서는 pandas에서의 데이터 병합에 대해 알아보았다.
정리하자면 merge와 join 메서드는 각각 열과 인덱스를 기준으로 데이터프레임을 결합하는 데 사용되며, concat 메서드는 여러 데이터프레임을 단순히 연결하는 데 사용된다.
데이터 병합은 간단한 개념으로 보일 수 있으나, 실제로는 복잡한 데이터 구조를 다루는 데 필요한 다양한 옵션과 상황들을 고려해야 한다. 이러한 고려 사항들을 이해하고 적절히 활용하는 것이 중요하다.
필자도 작성하면서 다시 공부가 됐지만, 다시 봐도 간단해 보이긴 하지만... 막상 해보려 하면 또 간단할 거 같진 않다...😂
실제로 많이 해보긴 해야 할 것 같다.
정리하자면 merge와 join 메서드는 각각 열과 인덱스를 기준으로 데이터프레임을 결합하는 데 사용되며, concat 메서드는 여러 데이터프레임을 단순히 연결하는 데 사용된다.
데이터 병합은 간단한 개념으로 보일 수 있으나, 실제로는 복잡한 데이터 구조를 다루는 데 필요한 다양한 옵션과 상황들을 고려해야 한다. 이러한 고려 사항들을 이해하고 적절히 활용하는 것이 중요하다.
필자도 작성하면서 다시 공부가 됐지만, 다시 봐도 간단해 보이긴 하지만... 막상 해보려 하면 또 간단할 거 같진 않다...😂
실제로 많이 해보긴 해야 할 것 같다.
반응형
'Python > Pandas' 카테고리의 다른 글
| ChatGPT로 Python pandas 알아보기 (9) : 기초통계량 (4) | 2023.06.27 |
|---|---|
| ChatGPT로 Python pandas 알아보기 (7):결측치 처리 (6) | 2023.06.13 |
| ChatGPT로 Python pandas 알아보기 (6):데이터 그룹화 및 집계 (0) | 2023.06.12 |
| ChatGPT로 Python pandas 알아보기 (5):데이터 정렬 (5) | 2023.06.11 |
| ChatGPT로 Python pandas 알아보기 (4):DataFrame method (3) | 2023.06.10 |





ChatGPT에게 데이터 병합에 대해 설명해달라고 했고 그 내용을 정리해 보았다.
우선 데이터 병합(Merge)이란 두 개 이상의 데이터(테이블)를 특정 기준에 따라 합치는 것을 의미하며, 이때 기준이 되는 열을 키(key)라고 부른다.
먼저 샘플 데이터프레임은 아래와 같다.