groupby 메서드는 데이터를 그룹으로 분류하는 데 사용된다. 이 메서드는 SQL의 GROUP BY 구문과 유사한 기능을 수행한다. 즉, 특정 열(들)을 기준으로 데이터를 그룹화하고, 이러한 그룹에 대해 집계 함수(sum, mean, count 등)를 적용할 수 있다.
# 기본 사용법
df.groupby('column_name')
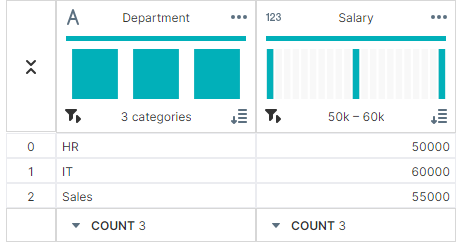
만약, Department 열을 기준으로 그룹화한다면,
# Department 열을 기준으로 그룹화
grouped = df.groupby('Department')
▶ 출력 결과
grouped는 그룹화된 데이터를 나타내는 객체이다. 이 그룹화된 데이터를 확인하려면 아래처럼 for 문으로 확인해 볼 수도 있다.
for name, group in grouped:
print(name)
print(group)
▶ 출력 결과
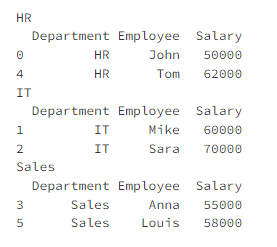
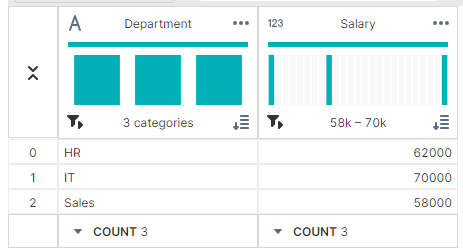
✔ 특정 그룹 선택:get_group(GroupName) get_group() 메서드를 사용하여 특정 그룹의 데이터만 선택하여 확인할 수 있다.
HR_group = grouped.get_group('HR')
▶ 출력 결과
집계 함수
groupby()와 함께 다양한 집계 함수를 사용할 수 있다.
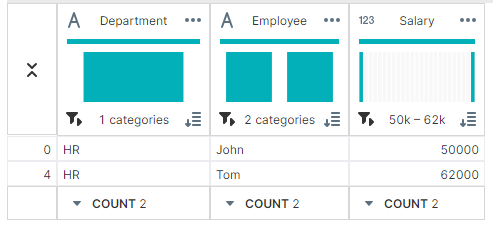
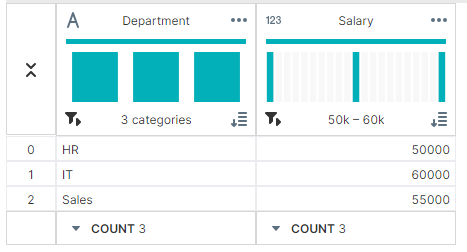
✔ 합계:sum()
total_salaries = grouped['Salary'].sum()
▶ 출력 결과
✔ 평균:mean()
average_salaries = grouped['Salary'].mean()
▶ 출력 결과
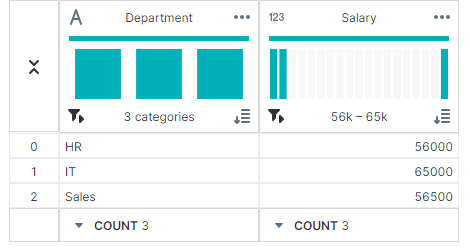
✔ 최댓값:max()
max_salaries = grouped['Salary'].max()
▶ 출력 결과
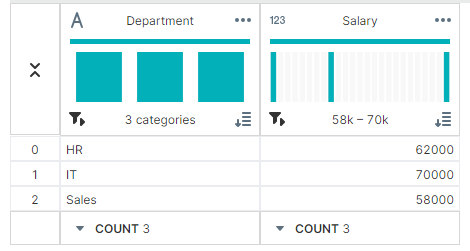
✔ 최솟값:min()
min_salaries = grouped['Salary'].min()
▶ 출력 결과
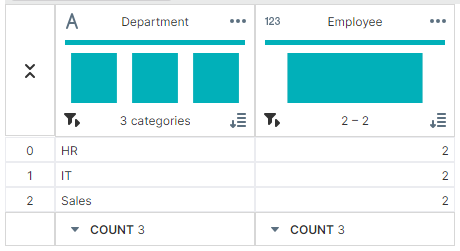
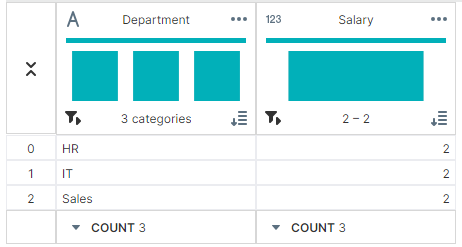
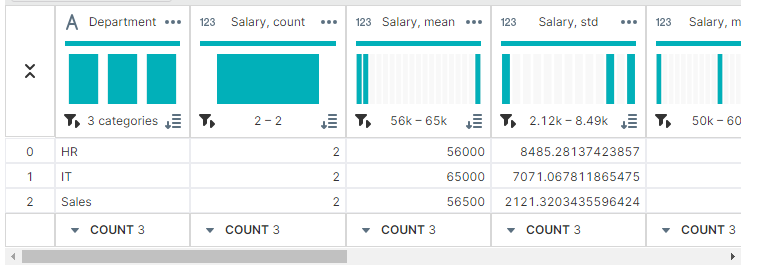
✔ 개수:count()
employee_count = grouped['Employee'].count()
▶ 출력 결과
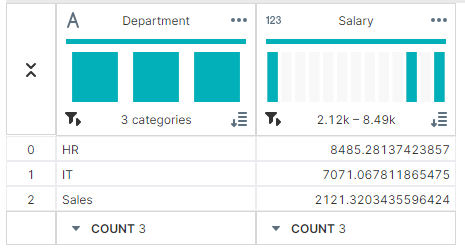
✔ 표준편자:std()
salary_std = grouped['Salary'].std()
▶ 출력 결과
✔ 분산:var()
salary_var = grouped['Salary'].var()
▶ 출력 결과
✔ 첫 번째 값:first()
salary_first = grouped['Salary'].first()
▶ 출력 결과
✔ 마지막 값:last()
salary_last = grouped['Salary'].last()
▶ 출력 결과
✔ 고유한 값의 개수:nunique()
salary_nunique = grouped['Salary'].nunique()
▶ 출력 결과
✔ agg() 메서드 agg() 메서드는 aggregate의 약자로, pandas의 DataFrame이나 GroupBy 객체에 다양한 집계 연산을 적용하는 데 사용된다. 이 메서드를 사용하여 여러 집계 함수를 한 번에 적용할 수 있으며, 각 열마다 다른 집계 함수를 적용하는 것도 가능하다. agg() 메서드는 데이터 분석에서 매우 유용하며, 복잡한 집계 연산을 간단하고 효율적으로 수행할 수 있게 해준다.
# 기본 사용법
result = dataframe_or_groupby.agg({
'column1': ['function1', 'function2', ...],
'column2': ['function3', 'function4', ...],
...
})
dataframe_or_groupby
집계를 적용할 DataFrame 또는 GroupBy 객체
column1, column2...
집계를 적용할 열의 이름
function1, function2...
적용할 집계 함수의 이름이나 함수 객체
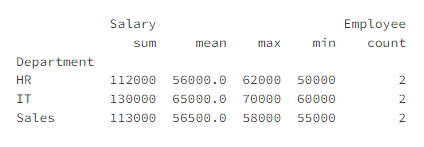
# 여러 집계 함수를 한 번에 적용
result = grouped.agg({
'Salary': ['sum', 'mean', 'max', 'min'],
'Employee': ['count']
})
▶ 출력 결과
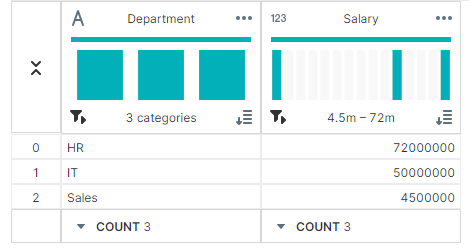
✔ 사용자 정의 함수 적용 agg() 메서드를 사용하여 사용자 정의 함수를 적용할 수 있다. 만약, 각 Department 그룹 Salary 범위를 계산하려면,
이번 포스트에서는 ChatGPT를 통해 pandas 라이브러리의 groupby에 대해서 알아보았다. 작성하면서 agg() 메서드에 대해서는 처음 알았는데 유용하게 사용해 볼 수 있을 것 같다. 특히 사용자 정의 함수 적용이 가능했다니... 이번에도 역시 개인적으론 도움이 많이 된 것 같다.










ChatGPT를 통해 데이터를 그룹화하는 메서드와 집계하는 메서드에 대해 출력 후 해당 내용을 정리했다.
데이터프레임의 샘플 코드는 아래와 같다.